

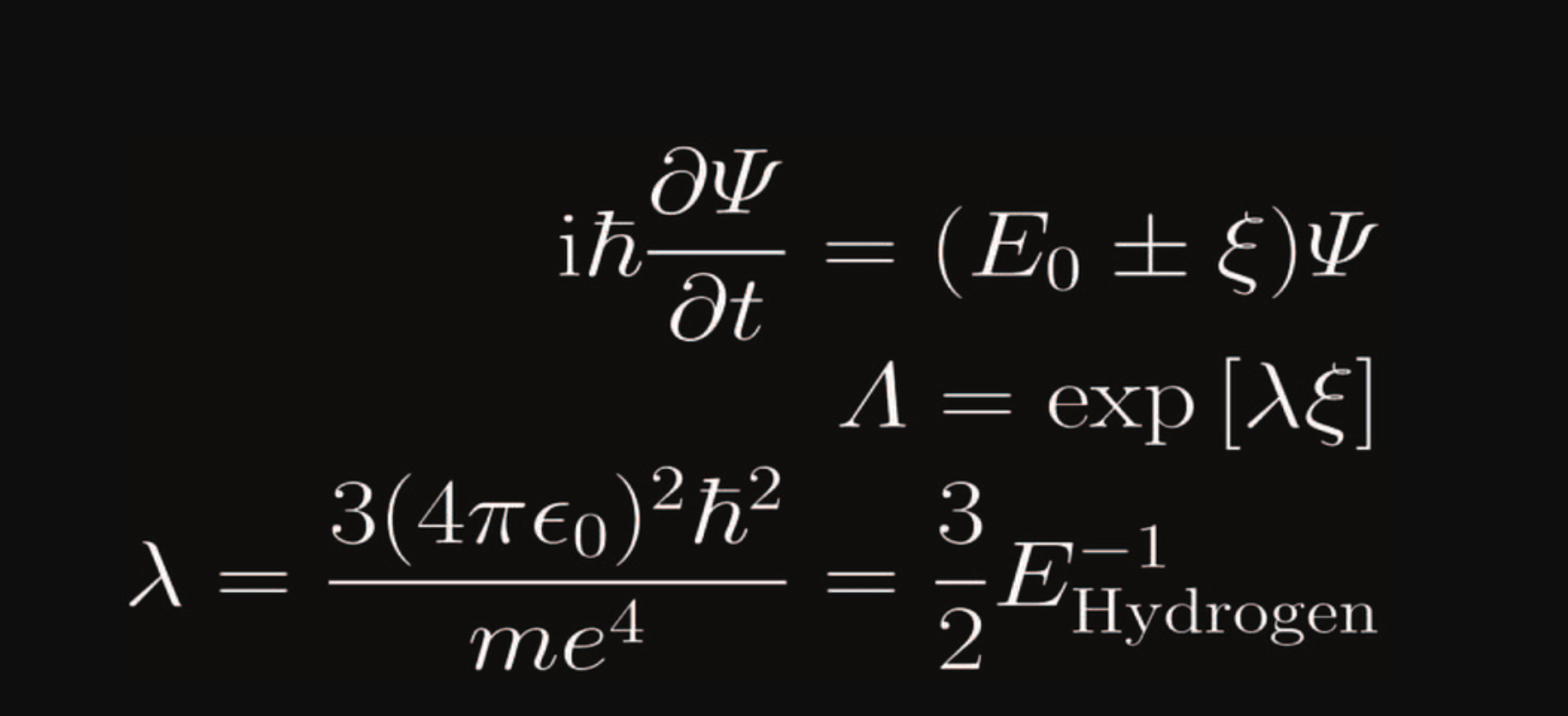


The Theory of Matter and Its Role in Everyday Life
Matter is the foundation of everything we see, touch, and interact with in the universe. It is composed of atoms and subatomic particles, which follow the laws of physics and chemistry to form the physical world. The study of matter, from the tiniest quantum particles to vast celestial bodies, is one of the most fundamental pursuits of science. But how does this theory apply to our daily lives? The answer lies in the practical applications of material science, physics, and chemistry, all of which shape the technology, health, and sustainability of our world.
Understanding the Basics of Matter
At its core, matter is anything that has mass and takes up space. Scientists categorize matter into four fundamental states—solid, liquid, gas, and plasma—each with unique properties determined by the arrangement of atoms and molecules. Advances in quantum mechanics and particle physics have revealed even deeper complexities, such as the existence of quarks, neutrinos, and the Higgs boson, which give mass to particles.
Theories of matter have led to remarkable scientific breakthroughs. The periodic table, for instance, organizes elements based on atomic structure and properties, allowing chemists to predict how substances interact. Similarly, Einstein’s equation, E=mc2E=mc^2E=mc2, showed that matter and energy are interchangeable, a principle that has fueled nuclear power and medical imaging technologies like PET scans.
The Impact of Matter on Daily Life
While the study of matter may seem abstract, it directly influences countless aspects of our everyday experiences.
- Technology and Innovation
The materials used in smartphones, computers, and even clothing are the result of deep scientific understanding of matter. Semiconductors, for example, are at the heart of modern electronics, enabling everything from microchips to solar panels. The discovery and manipulation of new materials, such as graphene—a single layer of carbon atoms—continue to revolutionize fields like energy storage and flexible electronics. - Health and Medicine
The human body itself is a complex arrangement of matter, driven by biochemical reactions. Medical research relies on the study of molecular interactions to develop drugs and treatments. Understanding how matter behaves at the microscopic level allows for targeted drug delivery, MRI imaging, and even regenerative medicine, where scientists engineer new tissues and organs. - Environmental Sustainability
The composition of matter plays a crucial role in solving environmental challenges. Scientists develop biodegradable plastics, carbon capture technologies, and renewable energy solutions by studying the properties and transformations of materials. Advances in nanotechnology, for instance, allow for water purification methods that remove pollutants at the molecular level, improving global access to clean drinking water. - Space Exploration and the Universe
The study of matter extends beyond Earth, helping scientists understand the composition of planets, stars, and galaxies. Research in astrophysics and cosmology has uncovered exotic forms of matter, such as dark matter, which makes up a significant portion of the universe yet remains invisible to traditional detection methods. These discoveries not only expand our knowledge of the cosmos but also inspire new technologies that benefit life on Earth.
The Future of Matter Research
As scientific inquiry advances, the study of matter continues to evolve. Institutions like the Argonne National Laboratory (www.anl.gov) conduct cutting-edge research in material science, energy storage, and quantum computing. By exploring the fundamental nature of matter, scientists unlock new possibilities for technological innovation, healthcare improvements, and environmental sustainability.
Whether in the devices we use, the medicine we rely on, or the way we explore the universe, the theory of matter shapes every aspect of our existence. Understanding its principles allows us to appreciate the interconnectedness of science and daily life while driving progress toward a better future.

Exploring the Universe with IBM Supercomputers: Advancing Particle Physics
Particle physics, the branch of science focused on understanding the fundamental building blocks of matter and energy, has always relied on cutting-edge technology to make breakthroughs. One of the most vital tools in modern particle physics research is the use of high-performance supercomputers. Among these, IBM’s supercomputers have emerged as a leading force, enabling physicists to simulate, analyze, and interpret the complex behaviors of particles at an unprecedented scale.
The Role of Supercomputers in Particle Physics
Particle physics investigates phenomena that occur at subatomic levels, often involving energies and time scales beyond direct experimental observation. Experiments at facilities like the Large Hadron Collider (LHC) generate enormous datasets, capturing the aftermath of billions of high-energy particle collisions. Understanding these interactions requires immense computational power to simulate particle behaviors, analyze experimental data, and test theoretical models.
IBM’s supercomputers are uniquely suited for this task due to their exceptional speed, data handling capabilities, and advanced architectures. One such IBM system, Summit, has proven to be a game-changer in this field. As one of the most powerful supercomputers in the world, Summit delivers petaflop-scale performance, making it capable of performing millions of calculations per second—a necessity for tackling the challenges of particle physics.
IBM’s Summit Supercomputer and Particle Physics
IBM’s Summit, housed at Oak Ridge National Laboratory, has been instrumental in advancing particle physics research. With its hybrid architecture, combining IBM Power9 CPUs and NVIDIA GPUs, Summit is optimized for both high-speed computation and large-scale data processing. This configuration enables researchers to perform complex simulations that would otherwise be impossible with traditional computing systems.
In particle physics, Summit’s capabilities are applied in several critical areas:
- Simulating Quantum Chromodynamics (QCD): Quantum Chromodynamics is the theory that describes the strong force, one of the four fundamental forces of nature. The strong force binds quarks and gluons into protons and neutrons, which in turn form the nuclei of atoms. Simulating QCD involves solving highly complex equations on a lattice—a process known as lattice QCD. Summit’s computing power has allowed physicists to simulate these interactions with unprecedented precision, helping to understand phenomena like the mass of protons and the behavior of exotic particles.
- Dark Matter Research: Particle physics extends beyond the visible universe into the mysterious realm of dark matter and dark energy. Summit’s ability to process massive datasets and simulate hypothetical particles has contributed to models exploring how dark matter interacts with ordinary matter. These insights are critical for experiments attempting to detect dark matter particles directly.
- Analyzing High-Energy Collision Data: Experiments at the LHC produce immense volumes of data during particle collisions. Summit helps researchers sift through this data to identify rare particle interactions and potential evidence of new particles, such as those predicted by supersymmetry or other beyond-the-Standard-Model theories.
- Studying Neutrinos: Neutrinos are among the most enigmatic particles in the universe, and understanding their behavior could unlock answers to fundamental questions about the universe’s origin and composition. Summit is used to simulate neutrino interactions and analyze data from neutrino detection experiments.
Beyond Computation: AI and Machine Learning
IBM’s supercomputers also leverage artificial intelligence (AI) and machine learning (ML) techniques to accelerate particle physics research. By training ML models on experimental data, researchers can identify patterns and anomalies that might otherwise go unnoticed. For example, AI-driven analysis can help pinpoint rare particle decay events or optimize detector designs for future experiments.
Collaboration and Future Prospects
IBM’s partnership with global research institutions ensures that supercomputers like Summit remain at the forefront of particle physics. As experimental facilities like the High-Luminosity LHC come online, the demand for advanced computational resources will only grow. IBM is already developing next-generation supercomputers, such as those based on quantum computing, which promise even greater capabilities for solving the mysteries of particle physics.
Conclusion
IBM supercomputers have revolutionized the field of particle physics, providing the computational muscle needed to explore the universe’s smallest components and most profound mysteries. By enabling simulations of complex theories, processing vast datasets, and incorporating AI-driven insights, IBM’s systems have become indispensable in the quest to understand the fundamental nature of reality. As technology advances, so too will our ability to uncover the secrets of the subatomic world, guided by the unparalleled power of IBM’s innovations.

The Role of Particle Physics in Home Air Conditioning: A Surprising Connection
When we think of particle physics, we often imagine complex experiments in massive laboratories like CERN, where scientists study the building blocks of the universe. However, particle physics, alongside other scientific disciplines, has indirectly contributed to technologies that impact our daily lives—including home air conditioners. While air conditioning might seem far removed from the subatomic world, its development has roots in scientific principles involving thermodynamics, quantum mechanics, and material science—all areas influenced by particle physics.
The Science Behind Air Conditioning
Air conditioners rely on the principles of thermodynamics to transfer heat from one place to another. The primary process involves a refrigerant that cycles between liquid and gas phases within a closed system. Key components such as the compressor, condenser, and evaporator facilitate the heat exchange. This process cools the air inside a home while expelling heat outside.
Several core scientific advancements made this technology possible, and particle physics has played an indirect but essential role in many of these breakthroughs:
- Quantum Mechanics and Refrigerant Behavior: The development of efficient refrigerants relies on an understanding of molecular behavior and energy transfer at a fundamental level. Particle physics, through its exploration of quantum mechanics, has deepened our understanding of how particles like electrons behave in various states. This knowledge has informed the design of molecules that can efficiently absorb and release heat energy without breaking down or becoming harmful to the environment.For example, refrigerants like hydrofluorocarbons (HFCs) are engineered using principles derived from quantum-level interactions. Scientists study the specific energy states of molecules and how they interact with electromagnetic radiation, much of which overlaps with particle physics research.
- Semiconductors and Control Systems: Modern air conditioners are equipped with sophisticated electronic control systems that regulate temperature and optimize energy usage. These systems rely on semiconductors, materials whose properties were first understood through research in quantum physics and particle interactions. The development of semiconductors was heavily influenced by the study of particle behavior in solid-state physics—a field deeply intertwined with particle physics. Technologies like temperature sensors, microcontrollers, and inverters owe their efficiency and miniaturization to advances in particle physics, which helped explain how electrons move through different materials under various conditions.
- Advanced Materials and Energy Efficiency: Materials used in air conditioning systems, such as heat exchangers and insulation, have benefited from particle physics research. Particle accelerators, tools developed for fundamental physics experiments, have been repurposed for material science applications. For instance, synchrotron light sources allow scientists to analyze materials at the atomic level, leading to the development of more efficient and durable components.Copper and aluminum, key materials in heat exchangers, have been optimized through this research. Innovations in thin-film coatings, derived from particle physics studies, enhance thermal conductivity and corrosion resistance, making air conditioning systems more effective and long-lasting.
Particle Physics and Environmental Impacts
Particle physics has also played a role in addressing the environmental challenges associated with air conditioning. Early refrigerants like chlorofluorocarbons (CFCs) were found to deplete the ozone layer, leading to international agreements such as the Montreal Protocol to phase them out. Developing safer alternatives required a deep understanding of molecular interactions with high-energy particles, such as ultraviolet photons in the atmosphere.
Researchers used principles from particle physics to design refrigerants that are less likely to interact with atmospheric ozone. These efforts resulted in the creation of hydrofluoroolefins (HFOs), which have a much lower global warming potential (GWP) than earlier substances. By modeling how these molecules behave under energetic conditions, scientists ensured that they would perform efficiently while minimizing environmental harm.
Heat Pumps and Renewable Energy Integration
Another area where particle physics intersects with air conditioning is in the development of heat pumps, which use the same principles as air conditioners but can both heat and cool a space. Advances in particle physics have contributed to breakthroughs in energy storage and conversion technologies, enabling heat pumps to integrate more seamlessly with renewable energy sources like solar and wind.
Superconducting materials, a product of particle physics research, hold promise for future heat pump systems. These materials, which can conduct electricity without resistance at low temperatures, could revolutionize energy transfer and storage in heating and cooling technologies.
Computational Modeling and Simulations
Modern air conditioning systems are designed using computational modeling tools that simulate heat transfer, fluid dynamics, and energy consumption. These tools rely on algorithms originally developed for particle physics simulations. High-performance computing systems used in physics research have been adapted to model complex systems like air conditioning units, enabling engineers to optimize designs for efficiency and performance.
Conclusion: A Surprising Interplay of Sciences
While particle physics may not seem directly connected to the comfort of a cool home, its influence is undeniable. From the quantum mechanics underlying refrigerant design to the development of advanced materials and electronic components, the contributions of particle physics are woven into the fabric of air conditioning technology. Furthermore, its role in addressing environmental challenges ensures that these systems can evolve sustainably.
The interplay between particle physics and other sciences underscores the interconnectedness of human knowledge. Technologies like air conditioning, which we often take for granted, are the result of centuries of exploration and discovery across multiple disciplines. As particle physics continues to push the boundaries of what we understand about the universe, its indirect contributions to everyday technologies will undoubtedly grow, making life more comfortable, efficient, and sustainable. And if you want a really good ac repair service there’s a local company named Quick Fix Air Repair that is amazing and helped me out over the summer. 5 star service from them.

Particle Theory: Decoding the Universe’s Building Blocks
When I explain particle theory to someone, I often see a spark of curiosity in their eyes. And that’s exactly why I love talking about it. To me, particle theory is like the ultimate treasure map, leading us to the most fundamental truths about the universe. Let’s dive into this exciting world together, shall we?
At its core, particle theory is the study of the smallest building blocks of matter and the forces that govern their interactions. If atoms are the bricks of the universe, then subatomic particles—like quarks, leptons, and bosons—are the grains of sand that make up those bricks. The Standard Model of particle physics, which I like to think of as our guidebook, categorizes these particles into two main groups: fermions (the matter particles) and bosons (the force carriers).
Now, let’s talk about quarks and leptons. Quarks are the particles that make up protons and neutrons, which in turn form the nuclei of atoms. Leptons include the electron, which orbits the nucleus, and its more elusive cousins, like the neutrino. The fascinating thing about these particles is that they’re incredibly tiny and behave in ways that defy our everyday experiences. For instance, neutrinos are so ghostly that billions pass through your body every second without you noticing—isn’t that incredible?
But particle theory isn’t just about identifying particles; it’s about understanding how they interact. This is where bosons come in. These particles mediate the fundamental forces of nature: the electromagnetic force, the strong and weak nuclear forces, and gravity. Take photons, for example. They’re the bosons responsible for electromagnetic interactions, which means they’re the reason we can see light or send messages across the internet. Then there are gluons, which hold quarks together inside protons and neutrons. Without them, the universe as we know it wouldn’t exist.
One of the most thrilling moments in particle physics happened in 2012 with the discovery of the Higgs boson. Dubbed the “God particle” by some, the Higgs boson confirmed the existence of the Higgs field, an invisible field that gives particles their mass. I remember watching the news from CERN and feeling a rush of excitement. It was a moment that reminded me why I became a scientist: to be part of this grand adventure of discovery.
And yet, there’s so much we don’t know. Dark matter and dark energy, which make up most of the universe, remain mysterious. We’ve detected their effects, but we don’t yet know what they’re made of. Similarly, questions about the nature of neutrinos and whether there are particles beyond the Standard Model keep us on our toes. Every day in this field feels like uncovering a new piece of the puzzle, and that’s what makes it so exciting.
Particle theory also connects to the big picture in surprising ways. For example, the same principles that describe subatomic particles help explain phenomena in the cosmos, like black holes or the early moments of the Big Bang. It’s humbling to think that by studying the smallest components of the universe, we’re also learning about its grandest scales.
I hope this glimpse into particle theory inspires you to look at the universe a little differently. Whether it’s the light from your screen or the air you breathe, everything is connected by the same fundamental particles and forces. And for me, knowing that is both humbling and awe-inspiring. So, let’s keep asking questions, exploring the unknown, and marveling at the intricate dance of particles that make up our world.
Atomic Theory: The Building Blocks of Reality
Throughout my career as a scientist, I’ve always been captivated by the idea that all matter—everything we see, touch, and experience—is composed of atoms. It’s a concept that’s been central to our understanding of the universe, and yet, it’s still evolving. I often think about how far we’ve come since Democritus first mused about the existence of indivisible particles over two thousand years ago. His early ideas were just the seeds of what would become one of the most significant scientific theories of all time.
Fast forward to the early 19th century, and we meet John Dalton, whose work laid the foundation for modern atomic theory. Dalton proposed that all matter is made up of atoms, and these atoms combine in fixed ratios to form compounds. It was a groundbreaking revelation, and yet, it was only the beginning. I find it fascinating how his ideas were soon built upon by others like J.J. Thomson, who discovered the electron, and Ernest Rutherford, who revealed the structure of the atomic nucleus through his famous gold foil experiment. These discoveries transformed our understanding of what atoms are and how they function.
Niels Bohr’s model of electron orbits added yet another layer of sophistication. I’ve always admired how his work bridged classical and quantum physics, providing a clearer picture of atomic structure. However, it was the advent of quantum mechanics in the 20th century that truly revolutionized atomic theory. Learning about the Schrödinger equation and Heisenberg’s uncertainty principle during my studies felt like unlocking the secrets of an entirely new dimension. These concepts showed us that electrons don’t travel in fixed paths but occupy regions of probability called orbitals—a notion that still boggles the mind.
Today, I’m thrilled to see how atomic theory is applied across so many fields, from nanotechnology to quantum computing. It’s remarkable to think that this fundamental understanding of matter helps us design tiny machines, develop advanced materials, and even tackle questions about the nature of reality itself. The implications of atomic theory seem endless, and every discovery feels like a step closer to unlocking the universe’s deepest mysteries.
As I reflect on our journey through atomic theory, I’m reminded of how interconnected science is. Each discovery builds upon the last, a testament to human curiosity and ingenuity. It’s a privilege to be part of this ongoing story, contributing, however modestly, to the legacy of understanding matter and the universe itself.
